
热门







Unity:揭秘数字人制作流程

数字人、虚拟形象的开发逐渐成为了新兴的技术议题,除了用于虚拟真人类形象,数字人的开发技术也能让角色表情更加生动,并且与观众互动。近期,Unity 技术团队制作了一个数字人Demo,很多业内人士都对此表示很有兴趣。
在Unity技术开放日-上海站上,Unity技术美术团队和技术团队就为大家介绍了这套基于 Unity的数字人生产流程。本文截取了其中的重点内容,如果你对数字人感兴趣不妨继续读下去。

“关于数字人脸部动画的制作,我们是用手机苹果 ARKit 方法进行面部表情捕捉的。”Unity TA团队的讲师Michael说道。

关于面部表情捕捉,这其实是另外一项技术,需要搭配苹果手机并使用Face Cap app软件,面部表情捕捉可以提供更高精度和细节的面部表情。通过使用 FBX 文件导件,可以用左边的白模把动作移动到角色上。

有关虚拟人创作主要分为两个主题,一个是渲染,一个是流程。接下来让我们看看渲染部分的内容。
虚拟人头发渲染
渲染这里首先要做的第一件事,就是用机器扫描一位真人。

Unity最近发布了全新的头发系统。基本头发制作流程是用Maya X-gen来做头发,X-gen主要工具也是现在很多影视团队的选择。之后再导到Unity里,生成tfx文件并在Unity里做头发的渲染。这套头发工具集成了AMD的头发技术,所以格外逼真。
在设置我们可以将不同的配置进行分组,每个配置文件都可以调细节。头发工具共分三个主要区,一个控制头发生成,一个控制头发动态,最后一个控制头发颜色, 美术师可以设计自己的组, 另外发尾部分的宽阔度也是可以动态调整的。
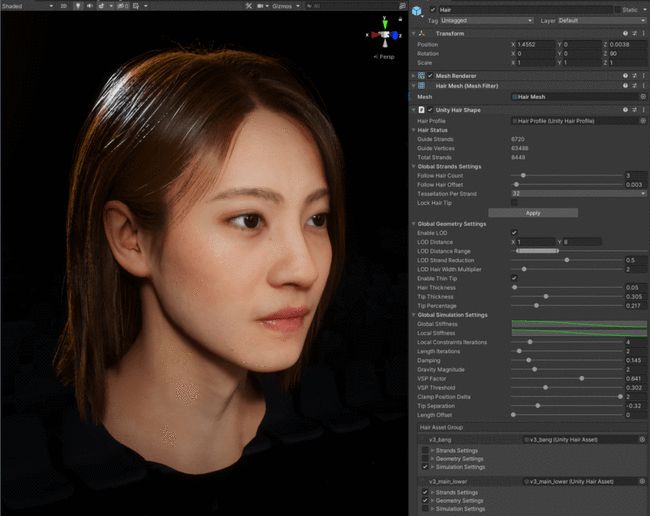
Unity将头发系统集成到HDRP(高清渲染管道)的头发材质里,用头发黑色素物理参数调出喜欢的发色,也可以用Dye Color直接加入一个你想要的任何颜色。
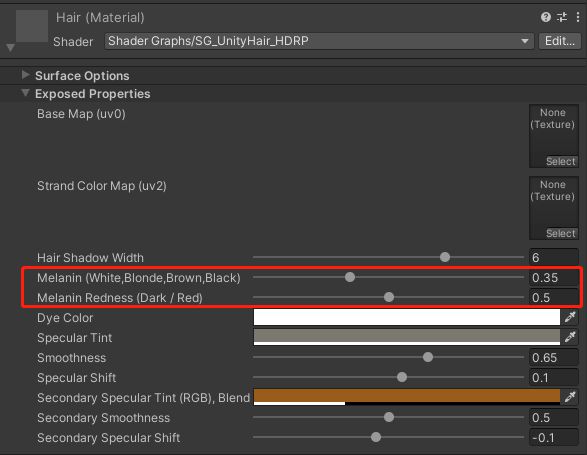
虚拟人制作流程
整个过程很简单,首先要根据FaceCode标准扫描极限表情,由模特在光场设备里做出那些表情,并被拍摄下来。剩下的事就是关于模型清理工作了,目前这部分也可以交给AI 算法来做从而实现节省人力的目的。
当我们清理出模型之后便需要开始做BlendShap(以下简称BS)拆分,关于这一部分方法有很多。FACS 在理论上人支持60个极限表情,从解剖学上讲,这60个表情可以非线性地组合出任意表情。但是我们做表情对话时,没办法只用60个表情就做出所需的所有表情。因此,这就涉及到BS拆解过程了。拆解的数量,与用户想追求的精度相关,也跟成本相关。在此项目中仅仅扫描了45个有代表性的极限表情,并拆分出了300多个BS。
有些算法有可能会进行重复拆解。实际上BS和BS不是完全叠加而回归到极限表情,它可能有些加和减的关系。如果AI将BS拆解成这样时就可能需要人为进行修正。比如一个嘴唇往下的动作是几个 BS 的组合,但是有一个BS是凹进去的,那么这个凹进去的就需要人为进行修正。因为这些极限表情和别的表情组合的时候会出问题。出现这种问题的时候,就需要人为进行修正,因此自动拆的算法还需要演进。
我们可以把表情贴图简单地划分为表情和微表情。表情上结构性的变化需要做在模型上,有些因为结构性变化而产生的挤压的纹理性变化的话,则需要做成贴图。贴图是Winkle Map,它是一 Normal的表情贴图,在不同表情间可进行切换,一张脸上往往会有五六张Winkle Map。
其实在扫描之后的数据是要把眉毛和一些眼睫毛从Map上去掉的,因为在做重拓扑和修模型时,这些都是噪声,是不需要的;但这些东西又在渲染时会用到。因此需要先进行删除,然后后面再把这些部分给加回去。像在此项目中,眉毛是用插片的方式来做的。
流程上还有修贴图,除了Winkle Map,还有一个Blood Flow Map(血流图),当你脸皱起来后,因为收挤压,某个地方的血流图会发生改变,那么这个地方的颜色会变深,这个表现在微表情中,也算在贴图中。所以关于微表情的贴图有两套,Winkle和Blood Flow,这是比较常规的操作。
这里是我们发现可以继续迭代的地方,修模型的部分,如果有足够的美术资源,其实是不用考虑算法的问题。
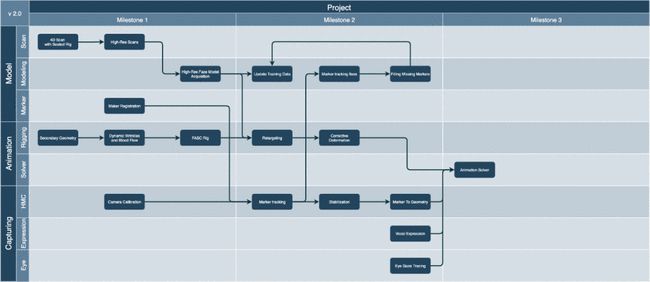
修完模型,拆完BS之后一般会做Rigiging 和模型Capture,因为用户最后想要的是快速生产高质量的表情动画。在Rigging中,相信大家一定会遇到一些这样的情况,比如Retargeting,这是因为不是模特去驱动他自己,而很可能是别人去驱动他,所以一定会有 Retargeting;还有就是Secondary Geometry 、Dynamic Winkle与Blood Flow,但是现在Unity目前还没做到Dynamic。目前本项目是在Shader中实现的,有关需要哪些贴图,让贴图对应表情等等一系列工作目前都是由用户自己来处理的,但这些简单枯燥的工作后期相信会有一些以AI的方式来实现。
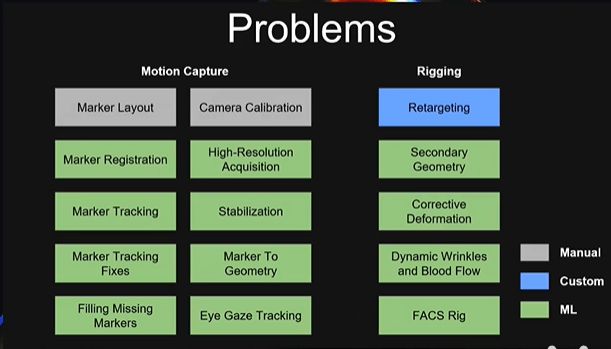
关于模型Capture ,目前有两个方案,用一些第三方提供的高精度结果去驱动模型。在这个项目中,Unity团队通过ARKit或者谷歌开源的AR core里face的model来做特征提取,从而驱动模型。但是模型capture也有可以迭代的地方,如果我们以Marker Based来驱动的话,后期就可能会需要修改一些Marker Tracking有问题的地方。如果用户选择自己做或者买第三方的Motion Capture设备也是可以的。因为有头盔的话就可以做更高质量的模型capture。
最后有关数字人的生态流程还有几个问题,一个是真人扫描数据的处理,就是模型的重建,那就会牵扯到算法的事;一些扫描得不太好的地方要修;还有就是贴图的重建。项目中出了刚才提到的两张贴图 Winkle Map 和 Blood Flow Map,其实我们还有一张提供颜色的图,Color Map。现在的设备都有偏正光,所以它会给你偏正的结果,但是实际上用户也要去做类似Delighting 的事,才能够得到一个没有光照的结果。
还有就是关于faceCode的扫描数据,目前我们能见到的虚拟人都是这样做的,就是模特去表演faceCode里的表情。做完之后进行BlendShap、Winkle Map、Blood Flow Map以及Face Rigiging的制作。而目前Face Rigiging 没有一致的标准,基本上是用户自己定义标准,能实现一个合理的、容易做动画的搭建就可以了。如果没有高质量的模型capture前提下,做动画很多时候还是需要人工手动修出来的,所以Face Rigiging这一步非常重要。
表情驱动会有一套控制器,人脸上有很多点,这里是参考 Unity 国外团队做《异教徒》项目的那一套来做的。传统做动画的方式就是上文中提到的以人工修帧为主的方式,还有面部驱动的方式,下一步Unity还将在这些流程之中试着加入一些AI的算法来优化整体流程。
下图是通过扫描得到的模型。我们可以清晰的看到在图中有这样那样各种问题。就是说我们虽然也是非常高精度的摄像机,基本摄像机有三套,一个负责颜色,一个负责光学,还有一个负责高速摄像,这三套相机可以提供人脸重建的非常高面素的mesh,但是拿到的 Geometry 也会有这样的问题,就比如像我们拿到的头是左边那样子的,但是模型的眼睛基本上全部坏掉了,这就需要建模师把它给手工修出来。还有耳朵也有可能是坏掉的,总之,扫描出来的模型会有很多坏掉的地方,这就是修模型时候后期要处理的事。

在修完模型之后,我们需要将模型重拓扑到一个合适的 Layout,还有就是上文中提到的扫描出来的模型也会提供Normal的贴图。贴图里有什么东西呢?这里其实也有一个值得迭代的点,就是这个贴图的使用率,实际上现在有很多做影视的公司,他们其实都在要求高分辨率的贴图,比如16K的贴图。但正是因为精度不够,实际上贴图的 layout 是不太好的。
制作表情,需要遵循以下步骤:
第一步,是先Remove掉那些我们不想要的Geometry,这里包含上文中说到的眉毛、眼睫毛这些,还有一些噪点,因为它扫出来的那个面素是一个巨大的开销,所以我们需要清理掉它。
第二步,在清理掉它之后,我们需要重拓扑,现在大家重拓扑都会用3D软件来做。
这里我们加Subdivide base mesh的原因是因为清理之后有一些地方需要增加细节,比如眼皮的地方,如果是双眼皮,一定是把它给叠起来的,因为在将来做动画时一定会有闭眼的时候。所以在眼皮处的Mesh的段数要加多一些,然后再去掉一些噪声和进行一些细节处理就可以了。
电话:010-50951355 传真:010-50951352 邮箱:sales@souvr.com ;点击查看区域负责人电话
手机:13811546370 / 13720091697 / 13720096040 / 13811548270 /
13811981522 / 18600440988 /13810279720 /13581546145

